ADDITIF :
CORRECTION ET PRECISION DES GRAPHIQUES
Ce petit document est un complément à des observations déjà faites dans les deux textes principaux du 5 Mai et du 19 Mai.
(1) présentation plus claire des observations de dépendance
(2) apport d’une AFC sur les seules comédies en vers.
LES OBSERVATIONS DE
DEPENDANCE
Voic une meilleure présentation des graphiques qui montrent la dépendance apparente de l’indice Labbé aux longueurs des textes considérés. J’avais employé une méthode de courbe, moins probante et plus compliquée que la solution toute naturelle du nuage de points.
Les données sont bien sûr les mêmes que celles déjà jointes en annexes dans les deux textes principaux (tableaux de résultats des indices Labbé sur le corpus Molière/Corneille et sur le corpus des Contes de Maupassant).
Dans tous ces graphiques, les ordonnées représentent l’indice Labbé, établi d’après les données lemmatisées par D.Labbé (corpus Corneille/Molière), ou les données brutes (Contes de Maupassant).
Dans ce graphique (1), sont repérés 2114 points,
correspondant aux 2114 couplages de textes possibles entre les 67 pièces du
corpus Corneille/Molière. Les abscisses sont les longueurs Na du texte le plus
court du couple. Le point très bas (indice 0.077) correspond au couplage
artificiel de deux versions de Psyché (voir à ce sujet notre document
n°2).
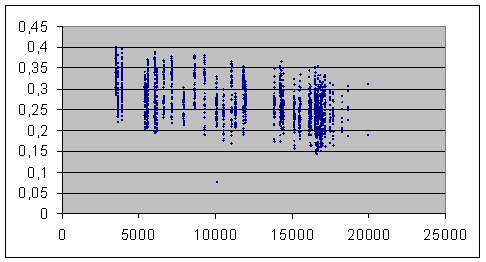
On repère très distinctement une tendance à la décroissance de l’indice à mesure que les textes s’allongent.
Impression largement confirmée par cet autre graphique (2), où les abscisses sont désormais les longueurs Nb du texte le plus long des mêmes 2114 couplages.
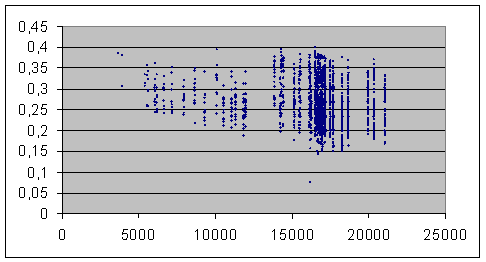
Il est à ce sujet intéressant de se reporter à notre observation la plus récente : appliqué aux ensembles Molière (364'891 mots) et Corneille (563'191 mots), l’indice Labbé chute à 0.197, soit très largement en-dessous de la moyenne des indices particuliers. Il nous semble que c’est un mauvais signe pour l’indépendance de cet indice à la longueur des textes (les longueurs ci-dessus sont des dimensions assez courantes pour des romans, par exemple).
M.Labbé nous a ensuite fait une réponse invoquant la diversité des genres représentés dans son corpus. Nous nous sommes demandé pourquoi cet argument, opposé à une entreprise de vérification, n’avait pas paru suffisant à MM.Labbé pour cesser leur propre expérimentation sur le corpus en cause, expérimentation qu’ils ont non seulement menée à terme, mais utilisée à titre de preuve pour une découverte extraordinaire et paradoxale.
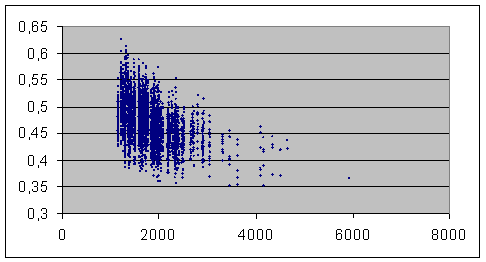
Mais nous avons aussi entrepris une vérification sur un corpus incontestable du point de vue du genre, celui des Contes de Maupassant (en excluant les trois plus longs, qui s’écartent nettement du reste du corpus de ce point de vue et risquaient de tomber sous le coup d’une disqualification du point de vue du genre ; et le plus court, qui a moins de 1000 mots – limite fixée par MM.Labbé).
En voici le résultat.
Graphique (3) : en abscisses, les longueurs Na du texte le plus court du couplage :
Graphique (4) : en abscisses, les longueurs Nb du texte le plus long du couplage
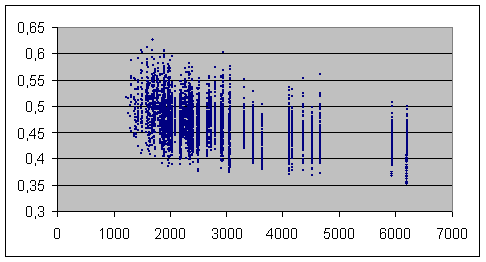
Voilà ce que nous avions voulu montrer et à quoi MM.Labbé sont bien en peine de répondre en défendant l’intérêt général et durable de leur indice.
On notera au passage que cette fois, les textes étant beaucoup plus courts, les indices sont beaucoup plus élevés : aucun couplage n’approche, même de très loin, le seuil d’attribution certaine fixé par MM.Labbé (0.2) ; autrement dit, si par malheur la moitié de ces contes avait perdu sa signature, aucun des 50 restants, clairement attribués à Guy de Maupassant, ne pourrait en prendre un quelconque égaré par la main pour le ramener au bercail…
LES COMEDIES EN VERS,
CLASSEES PAR L’AFC
Voici enfin une Analyse Factorielle des Correspondances que nous avons effectuée dans le même esprit que dans le document 1, mais en nous limitant cette fois aux seules comédies en vers des deux auteurs (analyse de la distribution des 2300 plus fréquents vocables – 96.5 % de la surface totale du corpus – dans les 23 comédies du corpus : 10 de Corneille, 2 versions de Psyché, 11 de Molière).
Table des numérotations :
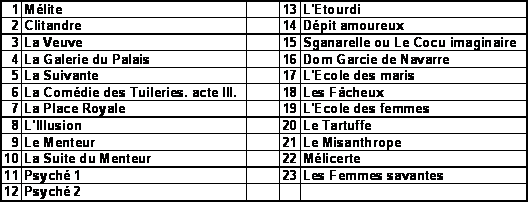
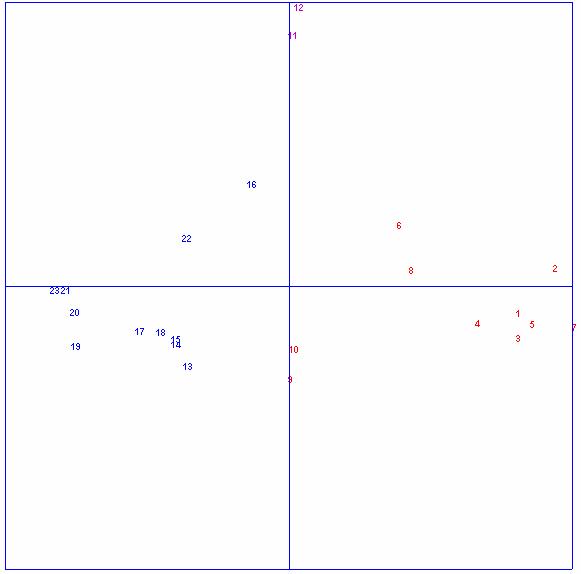
On y constate toujours la même claire différenciation des deux œuvres, avec un vide central très satisfaisant et, dans cet espace intermédiaire, les positions tout-à-fait remarquables des deux Menteurs **, et des deux fichiers de Psyché, qu’il restera à expliquer.
On constate aussi que Dom Garcie de Navarre se rapproche, dans ces conditions d’étude, du reste de Molière ; cela s’explique assez bien par le fait que ne sont plus là pour l’attirer vers Corneille, les comédies héroïques voire les tragi-comédies de Corneille.
D’où l’intérêt majeur que nous voyons à ce type de méthodes à titre d’exploration première : elles ne rendent pas compte de comparaisons entre deux textes dans l’absolu, mais sous la contrainte et donc avec les garde-fous de la dynamique d’un corpus constitué sur la base de l’hypothèse au travail. Elles laissent toute la place aux interprétations sérieuses et à la reformulation des hypothèses.
** Ici j'avais fait figurer cette parenthèse : (ultimes tentatives de Corneille dans le genre, marquées par l'influence désormais dominante de Molière) que je reporte en note, de crainte que le sens de l'humour soit aussi mesuré à certains autres lecteurs qu'il l'est à M. Labbé. La continuité de la phrase est ainsi mieux perceptible, même à un esprit soupçonneux.