MORNEILLE, COLIÈRE ET MESSIEURS LABBÉ
Lien vers : A propos des remarques récentes de M. Dominique Labbé
Lien vers : DIX QUESTIONS A DOMINIQUE LABBÉ, LE 27 MAI 2003par
Jean-Marie Viprey
Professeur des Universités, HDR
Directeur du laboratoire ELLIADD (Edition, Littératures, Langages, Informatique, Arts, Didactique, Discours)
EA 4661 de lUniversité de Franche-Comté
7ème et 9ème sections du CNU
(Sciences du langage, Langue et Littérature Françaises)
HISTORIQUE
Vendredi 25 Avril 2003, jai reçu un appel de M. Claude Blum, Professeur de Littérature à Paris-4 Sorbonne, et Directeur Editorial dHonoré Champion. Il avait été contacté par une journaliste du Monde, Mme Fabienne Dumontet, afin davoir son avis sur la polémique naissante autour de la « découverte » de MM Dominique et Cyril Labbé : Corneille était le « nègre » de Molière. Claude Blum me proposait dentrer en contact avec elle afin de lui procurer les éclaircissements dont elle avait besoin.
A ma grande honte, je confesse avoir été jusquà ce moment-là totalement ignorant de cette affaire. Mais dès que jeus pris connaissance des éléments du dossier, jacceptai bien volontiers. Je connais quelque peu les travaux de Dominique Labbé, depuis une dizaine dannées ; jaccorde une très grande importance à la qualité des rapports entre les sciences du langage et les sciences de la littérature, et tout spécialement au maintien et au développement du sens dans laventure conjointe et tumultueuse de linformatique et des textes.
A lorigine de cette polémique désormais publique, on trouve la publication dun article dans Le Dauphiné libéré, puis dans Le Figaro-Madame, et une intervention de D. Labbé au journal de 20 heures dune télévision nationale. On trouve également un certain nombre de pages web dont je donne quelques exemples ici :
http://www.01net.com/article/198041.html
http://www.deplaine.com/article.php3?id_article=984
http://villemin.gerard.free.fr/Langue/Texte.htm
http://livres.lexpress.fr/dossiers.asp?idC=5373&idR=4
http://gu.grenet.fr/1039710710130/0/fiche_actualite/
(cette dernière page sur le site institutionnel du Pôle Grenoble Université Recherche).
Courant avril, le Pr Georges Forestier (Paris-4 Sorbonne), publiait sur le site du Centre de Recherche sur lHistoire du Théâtre, dont il est Directeur, une réponse circonstanciée à Dominique Labbé. On trouvera ci-dessous ladresse web de cette réponse.
Dans la même période, des articles beaucoup plus mitigés que les premiers ont paru dans LExpress, puis surtout dans Le Point (http://www.lepoint.fr/litterature/document.html?did=128930)
qui se fit pour la première fois lécho de critiques et de désaccords issus de la sphère même de la lexicométrie universitaire (Charles Muller, Pierre Lafon, Etienne Brunet).
Au-delà de ce « tapage » médiatique (tout de même assez modéré encore), la polémique qui sest engagée est importante et mérite dêtre éclairée et organisée. Je me suis réjoui de lintervention dun journal comme Le Monde et Mme Dumontet, qui devait rencontrer Dominique Labbé, lui a demandé sil serait daccord pour nous recevoir ensemble, ce quil a accepté. Nous avons donc pris rendez-vous pour le mardi suivant (29 Avril), au domicile grenoblois de M. Labbé.
Entre temps, je lui ai expédié, par souci de clarté, un mail contenant les questions qui me préoccupaient et sur lesquelles je souhaitais débattre avec lui devant la rédactrice du Monde.
Le texte de ce mail, en date du 27.04.2003, est donné en annexe 1.
(à suivre )
LES VRAIS ENJEUX DUNE
AUTHENTIQUE POLEMIQUE
Le texte qui est à lorigine de cette affaire est un article en anglais de Dominique et Cyril Labbé, non traduit en français à ce jour :
« Inter-Textual
Distance and Authorship Attribution.
Corneille
and Molière »,
Journal of Quantitative
Linguistics, vol 8, n° 3, 2001, p 213-231.
Cette revue est publiée aux Pays-Bas (Swets & Zeillinger) et référencée notamment dans les ®Current Contents.
Nous allons commenter ce texte, que MM. Labbé sengagent à fournir à ceux qui le leur demanderont (http://www.upmf-grenoble.fr/cerat/Recherche/PagesPerso/Labbe.html).
Nous montrerons successivement :
(1) que lindice de distance proposé par MM. Labbé dans leur article, si nous avons bien compris sa formulation et les deux compléments qui sont indiqués dans le texte, mais non intégrés à la formule elle-même, nest pas fiable.
(2) que la lemmatisation des textes, présentée comme un préalable nécessaire, na quune incidence mineure sur les résultats et semble destinée à ralentir ou bloquer les tests de vérification envisagés par les autres chercheurs
(3) que léchelle de pertinence qui a permis à MM. Labbé daffirmer détenir une preuve pour lattribution certaine à Corneille de 16 pièces faussement signées de Molière, est inopérante et absurde
(4) que la démarche de MM. Labbé se situe aux antipodes de la scientificité et relève dune imprudence rarement rencontrée à ce stade en sciences humaines ; quils confondent allègrement preuves et présomptions, présomptions et faisceaux de présomptions.
(5) quil existe des méthodes éprouvées, simples et transparentes, unanimement reconnues, pour comparer les vocabulaires de nombreux textes en corpus et présenter clairement les résultats de ces comparaisons
(6) que ces méthodes sont sans doute à utiliser en première intention dans laide que la statistique lexicale peut apporter aux vraies recherches dattribution
En introduction, MM. Labbé proposent un mode de calcul qui donne une mesure standardisée de la distance réelle (standardized measure of the actual distance) entre deux textes, mesure qui entend se fonder sur la fréquence de chaque item (type) et non simplement sur sa présence (notion binaire : litem est, ou non, présent : 0/1 ). Et il asserte que cette mesure permet non seulement de montrer la différence entre les uvres de Corneille et de Molière, mais aussi de prouver que Corneille a probablement écrit bon nombre des pièces de Molière (it also proves that Corneille probably wrote a lot of Molières plays, souligné par nous). Dans cette formulation, la prudence (probably) est indubitablement subordonnée à limprudence (proves). Il suffit dôter ladverbe pour trouver ce qui est écrit sur la page http://gu.grenet.fr/1039710710130/0/fiche_actualite du site institutionnel Grenoble Université Recherche :
Le logiciel d'un chercheur de l'IEP montre
que Corneille était le nègre de Molière
page doù un lien pointe directement sur la page http://www.01net.com/article/198041.html où lon trouve des formulations sans la moindre nuance.
MM. Labbé proposent un calcul en plusieurs étapes.
(1) Après avoir établi la liste fréquentielle des items lexicaux, déterminer lequel des deux textes (A et B) est le plus long (B) (en terme doccurrence cumulée de ces items). Le quotient de Na (nombre total doccurrences de A) sur Nb devient un coefficient (u), affecté aux effectifs des items de B. Leffectif dun item de B, de Eib, est ainsi réduit à Eib(u). Si cet effectif corrigé est au moins égal à 1, il est cumulé à Nb qui servira au lieu de Nb lors de la phase de calcul de lindice.
(2) Pour tous les items de A, on mesure la différence entre leur effectif dans A, et leur effectif corrigé Eib(u). Cette différence est cumulée à la distance absolue, somme des différences deffectifs, à condition quelle soit au moins égale à 0.5
(3) Pour les items de B absents de A, et présentant un effectif corrigé au moins égal à 1 : [Eib(u) ≥1], cest cet effectif corrigé qui est cumulé à la distance absolue (en tant que différence avec zéro )
(4) La distance absolue est rapportée à une estimation de la longueur cumulée des deux textes, où Na sajoute à Nb tel que défini en (1). Ce quotient est une valeur fluctuant de 0 (le texte B a une liste fréquentielle identique, toutes proportions gardées, à celle de A) à 1 (aucun item de A nest employé dans B).
Ce calcul se programme aisément ; nous lavons fait sous ®Microsoft VBPro (environ 150 lignes, sans optimisation professionnelle : voir en Annexe 2). Nous lavons ensuite testé sur les corpus Corneille et Molière, lemmatisés par M. Labbé, qui nous les avait confiés. Nous retrouvons bien, sur les exemples mentionnés par larticle de MM Labbé, leurs indices à la 3ème décimale près. Par exemple, 0.183 entre LEcole des Femmes et Tartuffe.
Demblée, des observations inquiétantes simposent, bien que nous ayons respecté les recommandations de MM.Labbé, de ne pas inclure dans le test les textes très courts, déviter les différentiels de longueur supérieurs à 10 (en quotient), et de ne pas inclure dans le cumul de la distance absolue les valeurs absolues de Eia - Eib(u) inférieures à 0.5
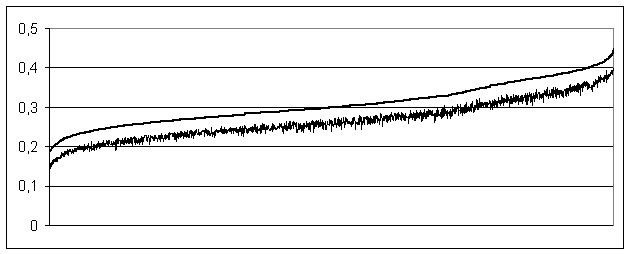
Les tests de cette première observation sont tous effectués dans un tableur, à partir dun tableau de données qui sera constamment formée comme le montre la figure 1 (les deux dernières colonnes contenant deux indices de distances calculés selon la formule de MM. Labbé : la première en comptant les formes graphiques, la seconde en comptant les lemmes).
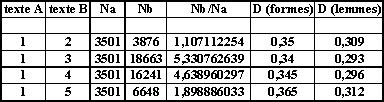
Fig.1 : extrait du tableau de contrôle des
résultats
Nous pouvons ainsi trier les lignes du tableau daprès 3 critères successivement : Na, puis Nb, puis Nb/Na, afin dobserver dans quelle mesure D(lemmes) est indépendant des divers paramètres bien connus pour influencer indument les mesures statistiques massives comme la « richesse lexicale », la « distance » ou la « connexion », etc. Un simple graphique muni dune courbe de tendance suffira à montrer les diverses corrélations, avant de les évaluer plus exactement. Ce genre de tests a lavantage dêtre compréhensible par tout un chacun.
Nous constatons tout dabord que lindice de distance nest pas insensible à la longueur du texte A (le plus court de la paire considérée). Voici en effet ce que donnent, rangés par ordre croissant de Na, les variations de D(lemmes) pour les 2114 couplages :
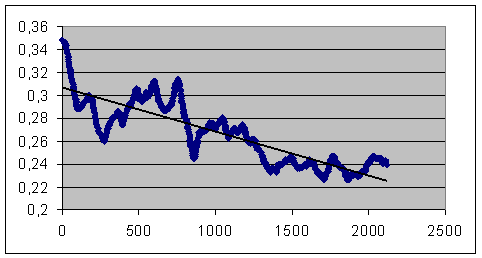
Fig.2 : Courbe de corrélation de Na et
de D(lemmes)
On constate donc une décroissance sévère et régulière de lindice de distance à mesure de laccroissement de la longueur du texte A.
Décroissance plus modérée, mais tout aussi manifeste, avec
laccroissement de la longueur du texte B :
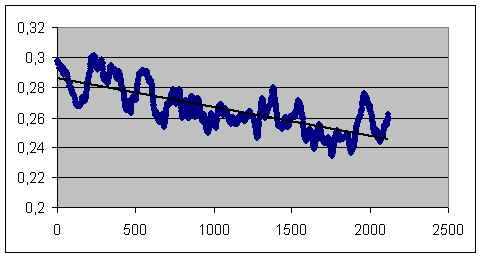
Fig.3 : Courbe de corrélation de Nb et
de D(lemmes)
Tout aussi inquiétante, la corrélation, directe cette fois, entre le résultat de distance et le quotient Nb/Na, dont MM. Labbé nous indiquaient pourtant de ne nous méfier quà partir de 10, et qui semble bien influencer lindice dès ses premières variations (pour indication, le millième couplage classé ci-dessus ne présente un quotient Nb/Na que de 1,234) !
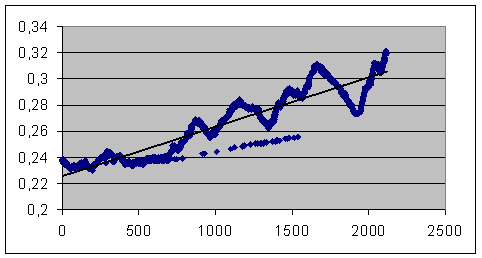
Fig.4 : Courbe de corrélation de
Nb/ Na et de D(lemmes)
Nous avons constaté la même triple déviation dans toutes les applications de nos tests, à des corpus comme ceux de Maupassant, de Balzac par exemple. Notons également quelles affectent tout autant les corpus séparés de Molière et Corneille, que le corpus mis en commun.
Nous ne sommes pas du tout étonnés de ces constats, pas plus que ne le seront ceux qui suent sang et eau sur ces problèmes depuis plusieurs décennies La dynamique des vocabulaires dépend beaucoup, entre autres (et beaucoup de conditions étant égales par ailleurs) de la longueur effective des textes considérés, et cest pourquoi on ne saurait admettre sans beaucoup de précautions et de vérifications une proposition comme celle qui préside à la technique de « réduction » du texte B aux dimensions du texte A chez MM.Labbé.
Nous sommes étonnés, en revanche, de voir présenter comme scientifique un appareillage aussi fruste et suranné, et de voir construire sur lui un échafaudage de conclusions téméraires.
Ces constats suffisant à disqualifier toute la démarche, nous pourrions en rester là.
Voyons cependant la suite.
2. LA
LEMMATISATION COMME ECRAN DE FUMEE
P.218, MM. Labbé stipulent que ces calculs, si probants par eux-mêmes, supposent que le texte ait été normalisé et étiqueté linguistiquement. Leur argument le plus développé est celui de la présence systématique des majuscules en début de vers. Sil ne sagissait que de cela, ne suffirait-il pas de les supprimer afin quen effet ce facteur ne vienne pas accroître artificiellement la distance lexicale entre vers et proses ? Cest dailleurs ce que lon fait couramment lorsquon cherche à établir rapidement le lexique dun corpus.
MM. Labbé ne développent pas du tout les arguments en faveur de la lemmatisation (reconnaissance et étiquetage lexical), mais ils en font une sorte de préalable. Dans une discussion avec Etienne Brunet, Dominique Labbé a dailleurs invoqué des lemmatisations différentes pour expliquer des résultats fortement divergents.
Or, sagissant dapplications très massives de la lexicométrie (comparaison en masse des vocabulaires de textes par paires), on peut montrer que cette lemmatisation est un « luxe » inutile. On peut même soupçonner quelle fonctionne comme un écran de fumée techniciste, apte à limiter (voire à décourager) les expérimentations et les tests de validation (pour refaire lexpérience Labbé sur Balzac ou Maupassant, il faudrait lemmatiser des centaines de milliers doccurrences ).
Il est donc intéressant de comparer les indices de distance obtenus, avec la même formule Labbé, selon que lon a travaillé sur les formes graphiques occurrentes (initiales normalisées, i.e. ramenées aux minuscules sauf pour les noms propres) ou sur les lemmes.
Il suffit de trier notre tableau sur le critère de la colonne D(formes) et dobserver la courbe des valeurs D(lemmes) ainsi ordonnées (la courbe régulière est celle des valeurs D(formes) )
Les valeurs D(lemmes) sont régulièrement inférieures à D(formes), la différence restant assez étonnamment constante (oscillant autour de 0,04). On voit bien cependant que la courbe de D(lemmes) est « rugueuse ». Cela montre que pour certains couplages de textes, la lemmatisation modifie la mesure de distance telle quon laurait obtenue avec les formes graphiques.
Si lon considère une courbe « lissée » par moyenne de 20 valeurs successives, loscillation maximale correspond à environ 0,023 et loscillation moyenne à 0,005.
Ce constat devrait amener lobservateur à une prudence renforcée quant à linterprétation des résultats ! En effet, la discussion théorique est loin davoir été menée à sa conclusion, sur la supériorité, linfériorité ou la complémentarité des divers niveaux de codage du texte. Or cest linverse : MM. Labbé affirment non seulement que « la » lemmatisation est plus fiable, mais même (au moins implicitement) que « leur » lemmatisation est « la plus » fiable.
Or le simple examen des fichiers lemmatisés fournis par M. Labbé montre bien quune certaine lemmatisation a été effectuée, parmi celles possibles ; et en particulier que les mots composés nont pas été traités, comme lindique cet extrait du début du Dépit amoureux (v.5) pour ladverbe du moins (3 lemmes ! ) :
du,de,81
du,le,71
moins,moins,60
pas plus que les formes passives (v.15) :
le,le,71
doute,doute,21
est,être,11
mieux,mieux,60
fondé,fonder,12
ou auxiliées en général
(v.1196) :
m',je,51
a,avoir,11
planté,planter,12
là,là,60
Voici dailleurs la liste complète des lemmes composés identifiés par M. Labbé pour lensemble des 928'000 occurrences du corpus de Corneille :

Que donneraient ces mêmes calculs sur des textes plus rationnellement lemmatisés ? Certainement des résultats massivement analogues, une courbe plus basse encore, mais tout aussi « rugueuse » par rapport à celle obtenue par la lemmatisation de M. Labbé : cest-à-dire ne pouvant certainement pas être interprétée pour chaque couplage individuel en termes absolus (seuils de « certitude »).
Ces considérations de bon sens autorisent à envisager les éventuels tests ultérieurs, sur de vastes corpus, sans être bloqués par lobstacle à court terme de la lemmatisation. Il suffira de relever les seuils de MM. Labbé de 0.04 afin de pouvoir les tester sur des textes « bruts ».
Venons-en maintenant à la partie
la plus délicate (si possible après ces deux groupes dobservations
préliminaires, déjà fortement disqualifiantes), à ce qui dans largumentation de
MM. Labbé a proprement déclenché ce quil faut bien
appeler une « affaire ».
Toujours p. 218, MM. Labbé nous informent que leur formule a été testée sur divers corpus, dun total de près de 10 millions doccurrences : discours politiques et syndicaux, textes littéraires de divers siècles, textes de presse. Ces tests étaient destinés à étalonner le système, ce qui a donné une échelle de distance et qui est paraphrasée dans un article accessible sur le site web de M. Labbé « Qui a écrit quoi ? ».
Cette échelle nous indique en
substance quau-dessous dune distance de 0.2, les deux textes sont du même
auteur, dans le même genre, sur le même thème, et que dans le cas dun scripteur
inconnu, lattribution auctoriale est
ici le traducteur marque un temps
darrêt, et préfère citer le texte en anglais afin de bien montrer linimitable
ambiguïté de MM. Labbé
:
in the case of an nunknown
writer, authorship attribution is quite sure (souligné par nous)
C'est-à-dire que MM. Labbé sont allés chercher ladverbe anglais le plus ambigu à cette place : quite dont chacun sait quil peut se traduire tout autant par complètement, tout-à-fait que par plutôt, assez. Notons que ladverbe ne figure pas dans le schéma de léchelle que lon voit p. 219 (il est question ici de Sure authorship attribution).
Ainsi voit-on naître un nouveau genre de discours « scientifique », la démonstration à modalité variable ! De cet énoncé « sérieux », dans une revue sérieuse, on peut ainsi passer insensiblement à des énoncés encore beaucoup moins prudents, tout en revenant sy réfugier lorsque le temps se gâte !
Mais M. Labbé nest pas toujours aussi prudent : dans larticle en français déjà cité, il écrit :
une distance inférieure ou égale [tout est dans
cette ultime précision !, notre note] à 0,20 indique que les textes
appartiennent au même registre et genre, quils
ont un thème unique et quils ont été écrits par un seul auteur
Il précise encore que, si par aventure il y avait deux auteurs distincts, lon pourra conclure avec certitude que le second aura plagié le premier ou quil laura utilisé comme « nègre ».
Dans larticle du JQL, on voit même que 0.4 est la distance-seuil pour le noyau commun minimal pour deux textes produits par un même auteur ; autrement dit, au-dessus de 0.4, les deux textes ne peuvent pas être du même ! Lun des deux devrait donc être exclu de luvre et viendrait donc grossir le juteux dossier des textes non attribués (MM. Labbé ne vont pas jusquà cette conséquence extrême) !
Car il se trouve que MM. Labbé nont jamais rencontré de cas qui contredise cette échelle ! Que comprendre ? En tout cas, quils nont pas testé leur échelle sur les corpus du théâtre du XVIIème siècle, puisqualors ils auraient rencontré plusieurs de tels cas, avant même de pouvoir soupçonner que Corneille était « le nègre de Molière » ! Cest ce qua très bien observé, de son côté, Georges Forestier.
Il est tout de même assez curieux dopposer une échelle de pertinence établie empiriquement sur 10 millions doccurrences (establish the [ ] distance scale empirically JQL p.218 bas), à deux des corpus les plus célèbres de la littérature française qui la contredisent manifestement, et linvalident ! Sauf dans lhypothèse où MM. Labbé avaient déjà de forts soupçons sur lauthenticité de la signature de Molière sur ses chefs-duvre.
Cest en effet pp.220 ssqq, une fois léchelle dressée, que MM. Labbé portent lestocade : depuis toujours, la rumeur disait que Molière nétait pas lauteur de ses pièces (since the beginning, it was rumoured that Molière was not the writer of his plays : on admirera ici encore la clarté de la formulation : de quel beginning sagit-il ? quel sens prend his ?); et depuis lors, le problème a été discuté maintes fois. Peu importe sans doute que le problème nait jamais été discuté par les spécialistes de Corneille, de Molière, du théâtre du XVIIème siècle
Afin de ne pas abuser des citations, ni de la patience du lecteur (qui peut se reporter à cet article du Journal of Quantitative Linguistics ref.supra - que M. Labbé sest engagé à lui procurer), allons à la conclusion (p.228) :
The Menteurs authorship is clearly
the same as most of Molières masterpieces.
MM. Labbé parlent encore ensuite des pièces que Corneille écrivit pour Molière (plays he wrote for Molière), avant de réconforter le malheureux démasqué : Molières historic importance is not at all minimized by it being almost certain that Corneille contributed to most of this masterpieces. Où lon constate la poursuite de cette oscillation entre certitude et hypothèse, qui permet en fait de laisser deux fers au feu, davoir des formules-choc pour attirer lattention et des réserves de prudence pour les jours moins fastes.
CONCLUSIONS : LE CADRE
METHODOLOGIQUE
De cette approche rapide, mais menée avec autant de rigueur que possible, et qui reste à approfondir si la nécessité sen fait sentir (notamment, si une discussion sinstaure dans laquelle MM. Labbé apportent de nouveaux arguments, ou de nouveaux soutiens) nous pouvons conclure sans le moindre doute que MM. Labbé ont eu tort dexposer sans plus de précaution ce quils pensaient être leurs « preuves ».
Quelles auraient été ces précautions, outre celles dune vérification plus attentive de la robustesse de leur « nouvelle » formule ?
Primo, laisser ouvertes les conditions dune discussion sérieuse avec les spécialistes du théâtre du XVIIème siècle, qui aurait sans doute évité au débat de tomber dans les ornières médiatiques. Ces conditions étaient dévoquer de fortes présomptions, de solides hypothèses, et non des certitudes à lemporte-pièce.
Secundo, engager cette même discussion au sein de la communauté des statistiques lexicales et textuelles. En effet, à notre grand étonnement, nous navons jamais vu présenter ces propositions et affirmations dans le colloque biennal auquel M. Labbé participe régulièrement, au Comité de Programme duquel il est même affilié, les JADT (Journées Internationales dAnalyse des Données Textuelles), pas plus quau Congrès de Rouen en 2002 (L'édition électronique en littérature et dictionnairique) où nous lavions invité. Il prétend, pour sen justifier, que la critique dattribution nintéresse personne en France, ce qui est évidemment tout-à-fait erroné : ce qui nintéresse pas les chercheurs et les éloigne, ce sont les systèmes daffirmations hâtives et péremptoires.
Ce serait surtout user avec plus de discernement de la notion de preuve. Cest dénaturer les recherches en statistique lexicale que dériger en argument décisif un résultat particulier, surtout si cet argument est de nature à intervenir dans une autre sphère disciplinaire, comme cest le cas ici. Même en admettant que lhypothèse dune attribution incertaine entre Molière et Corneille ait suscité lintérêt des critiques dix-septiémistes (ce qui nest pas le cas), la statistique ne pouvait intervenir dans la réflexion quà titre interdisciplinaire, complémentaire donc dautres arguments : ce que lon pourrait nommer une présomption et non une preuve, dans un faisceau de présomptions permettant déclairer la discussion.
De plus, il aurait été sage de faire intervenir un ensemble de calculs éventuellement convergents, au lieu de réduire la part des statistiques lexicales à ce quelles ont de plus fruste, et de les « ringardiser » de cette manière.
En effet, à côté de létude « en masse » du vocabulaire, notre communauté sattache depuis plusieurs années à développer une étude fine, réticulaire, fondée non pas sur les effectifs en masse, mais dabord sur létude des collocations, des cooccurrences, de la phraséologie, etc. Nous avons même établi que parler « en masse » du vocabulaire, cest le dénaturer, puisque le vocabulaire est fait de ces collocations, ce qui permet de comprendre et détablir que le terme feu, par exemple, nest pas le même chez Corneille, Molière et Racine.
Ces études « en masse », qui ont été le premier crédit des statistiques lexicales, sont aujourdhui à replacer dans un ensemble beaucoup plus riche et fécond.
On peut sétonner, dans le même ordre didées, de voir ainsi régler le sort de Molière et de Corneille sans que jamais un vers ne soit cité et étudié, ni pratiquement un mot, sans quaucune approche stylistique densemble ou de détail ne vienne à lappui : en résumé, cest la version la plus détestable et la plus caricaturale de lapplication des statistiques lexicales aux objets littéraires.
APOSTILLE : DES PREUVES ? EN
VOULEZ-VOUS ?
Depuis la première lecture de larticle de MM.Labbé, nous avons pressenti que cet appareillage technique était disproportionné avec son objet. Il existe en effet des méthodes universellement reconnues et efficaces destimer les distances lexicales à lintérieur dun gros corpus : ce sont les méthodes danalyse multidimensionnelle formalisées par J.-P.Benzécri depuis la fin des années 50. LAnalyse Factorielle des Correspondances (AFC) reste la plus simple et la plus robuste dentre elles.
Elle permet entre autres danalyser des matrices de données comme celles-ci :
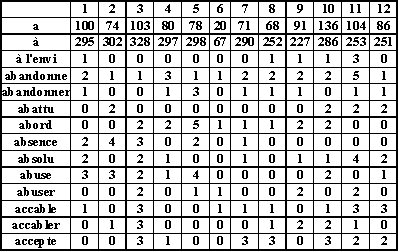
Fig.6 : Extrait dune matrice de distribution
lexicale.
où les colonnes correspondent aux divers textes du corpus, les lignes aux items lexicaux (ici, des formes graphiques), et les cellules à leffectif mesuré de litem dans chaque texte ; ce sont des matrices de distribution.
LAFC permet de comparer les profils (la constitution proportionnelle) des colonnes et/ou des lignes, de hiérarchiser linformation liée à ces profils, dopérer des groupements, et de les visualiser, notamment en deux dimensions. En dautres termes, elle permet ici de prendre un aperçu global sur les parentés lexicales massives entre les textes, avec un appareillage de relevé des données extrêmement simple.
Nous avons donc soumis le corpus Corneille/Molière, livré par M. Labbé, au relevé systématique des lemmes (puis, dans une 2ème étape dont il sera question plus loin, des formes brutes). Nous avons sélectionné les 2300 lemmes les plus fréquents à léchelle du corpus entier, et avons constitué la matrice de leur distribution dans les 67 textes (35 pour Corneille, 32 pour Molière), et soumis cette matrice à un algorithme dAFC tout-à-fait classique (en loccurrence, programmé dans ®Matlab par notre collègue le Pr Alain Lelu, membre comme M. Labbé du Comité de Programme de JADT).
Le résultat est tout-à-fait spectaculaire. Nous avons marqué en rouge les numéros correspondant aux pièces « communément attribuées à » Corneille, en bleu celles de Molière.
La nuance bleu foncé signale les pièces attribuées à Molière par MM. Labbé; le soulignement signale les pièces en prose; la nuance magenta signale les comédies de Corneille; la nuance bistre signale les tragi-comédies et comédies héroïques
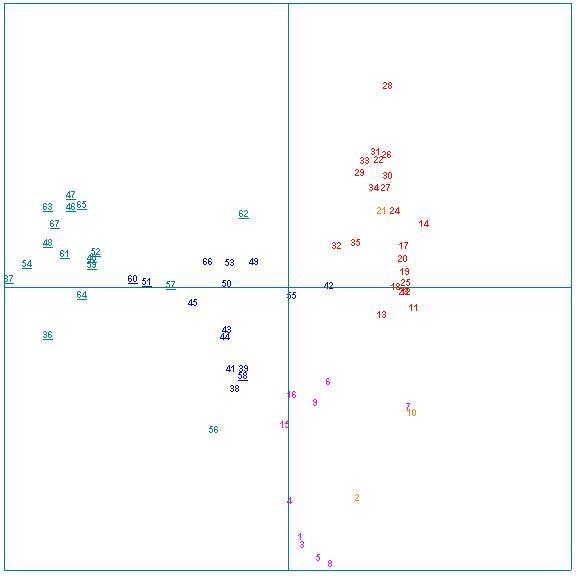
Fig.7 : AFC de la macro-distribution lexicale
(lemmes) dans les corpus Corneille (rouge) et Molière
(bleu).
Quobservons-nous ? Tout dabord, une admirable répartition des deux uvres de part et dautre sur laxe horizontal, qui correspond à la première passe de lalgorithme, donc à linformation la plus saillante. LAFC nous indique que, pour ce qui est des 2300 vocables les plus fréquents, qui couvrent à eux seuls 96.5 % de la « surface » totale du corpus et entre 94 et 97.5 % de celle de chacun des textes sans exception, les deux uvres sont parfaitement différenciées, au-delà même de toute espérance préalable.
Nous donnons en annexe la table des titres. Les deux pièces de Molière qui franchissent de peu laxe séparateur sont Dom Garcie de Navarre (n°42) et Mélicerte (n°55). Celles de Corneille qui sont dans une position intermédiaire sont les deux Menteurs (n°15 et 16). Quant aux uvres que M. Labbé attribue avec certitude à Corneille en raison de leur grande parenté avec les Menteurs, on voit que la plupart appartiennent bien à une zone de contact entre les deux uvres (bien que 51 Dom Juan - et 60 LAvare en soient assez éloignées déjà. Mais on peut tracer une ligne de partage bien claire et il y a plus de continuité interne dans la zone en bleu quil ny en a vers la zone rouge !
Si la zone centrale du graphe devait être attribuée à un auteur unique (Corneille), il y aurait donc une zone "Corneille" étendue aux points codés en bleu soutenu. Comment expliquer dans cette hypothèse que dans cette oeuvre "étendue", les textes écrits "pour" Molière se distribuent d'une manière aussi régulière, formant ainsi une zone clairement distincte, comme déterminée lexicalement par la signature de Molière ? N'est-il pas plus simple de commencer par explorer l'hypothèse d'un vocabulaire contraint par la prosodie ?
A-t-on seulement remarqué qu'à une exception près, les pièces les plus proches de la zone de Corneille sont toutes les pièces en vers de Molière ?
Les résultats sont pour ainsi dire identiques si, au lieu des lemmes de M. Labbé, nous prenons les formes graphiques brutes :
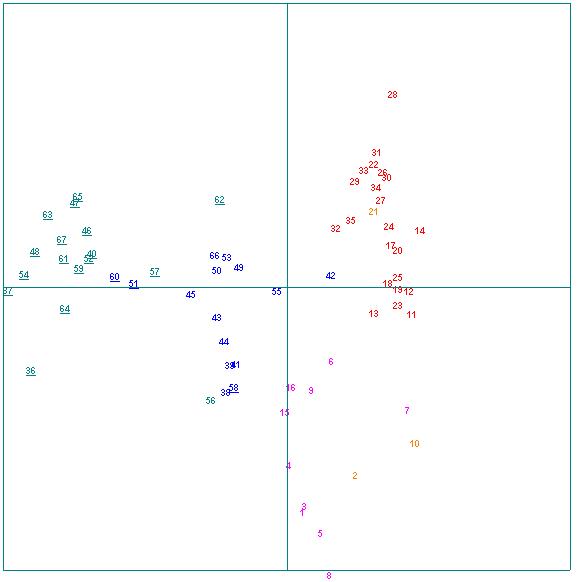
Fig.8 : AFC de la macro-distribution lexicale
(formes) dans les corpus Corneille (rouge) et Molière
(bleu).
Cette modalité exploratoire, incomparablement plus rapide, plus transparente, et qui a le grand avantage davoir été déjà expérimentée et validée, davoir prouvé sa robustesse face à de grandes distorsions de tailles individuelles des textes, nous permet de parvenir à des indications tout aussi pertinentes, mais aussi beaucoup plus complètes que létude individuelle des distances, à laquelle il manque précisément la pression et la norme de référence dun corpus constitué.
LAFC ainsi appliqué est dune robustesse insoupçonnée. Si, au lieu de considérer la distribution des 2300 items les plus fréquents, couvrant plus de 95 % du texte, nous excluons du calcul les 100 premiers (parmi lesquels de très nombreux outils grammaticaux), et restons ainsi avec 2200 items ne couvrant plus que 32 %, la distribution reste très similaire et en tout cas, pour notre problème, très indicative :
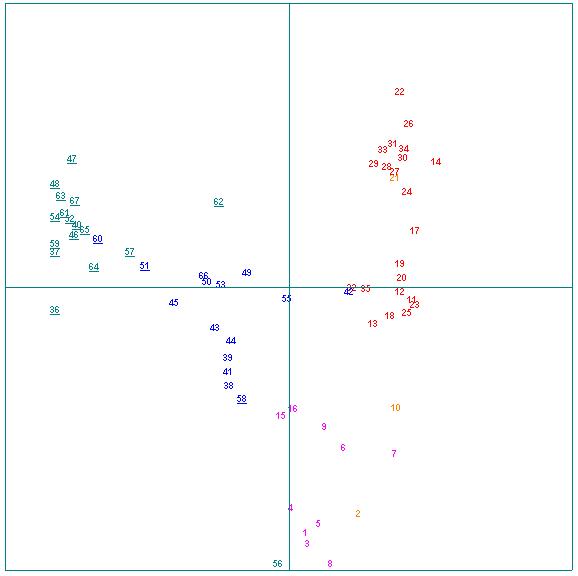
Fig.9 : AFC de la macro-distribution lexicale
(formes) dans les corpus Corneille (rouge) et Molière
(bleu).
Items des rangs 101 à 2300 par
effectifs.
Si nous retenons cette fois, toujours en excluant les 100 premiers, ceux qui ont servi au test précédent, mais à condition quils commencent par une lettre de A à E (couverture : 11 %) :
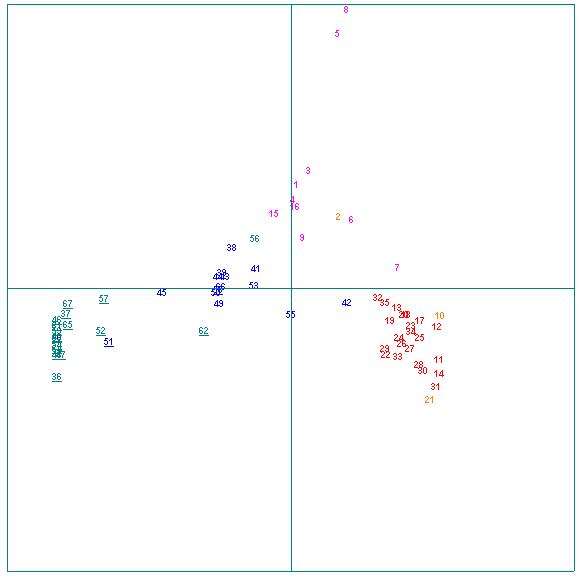
Fig.10 : AFC de la macro-distribution lexicale
(formes) dans les corpus Corneille (rouge) et Molière
(bleu).
Items des rangs 101 à 2300 par
effectifs, commmençant par A,B,C,D,E.
Certes des faits probablement aléatoires commencent à perturber la vision des distributions dans chacun des corpus : ici La Suivante (5) et La Place Royale (8) « écrasent », mais la séparation nette des deux uvres reste parfaitement lisible, avec les mêmes pièces dans les mêmes positions médianes.
Terminons avec une AFC de la distribution de 3000 items ayant des effectifs très médiocres : de 6 à 15 inclus. On ne couvre désormais que 3 % de la surface, et pourtant :
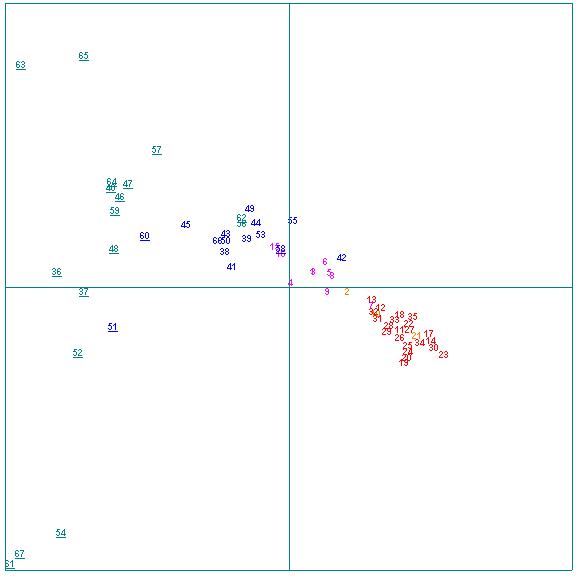
Fig.11 : AFC de la macro-distribution lexicale
(formes) dans les corpus Corneille (rouge) et Molière
(bleu).
Items deffectifs médiocres (6 à 15).
On notera que, sans doute, dans cette classe deffectifs, luvre de Molière présente une hétérogénéité visiblement plus grande (zone bleue) que celle de Corneille. Mais on notera que les deux zones demeurent remarquablement délimitées lune de lautre.
Cette stabilité est en même temps une preuve de la robustesse du mode de calcul et un bon indice du fait que, même en masse, les vocabulaires des deux uvres sont remarquablement différenciés, et cela dans toutes les classes de fréquence jusquaux relativement basses (beaucoup moins dune occurrence par texte).
Que nous considérions nimporte lequel de ces graphes, nous navons aucune raison de considérer quil y ait une zone des points bleus quil soit utile de « rendre » à la partie rouge du nuage pour améliorer la délimitation. Donc, aucune raison liée aux masses du vocabulaire pour faire de Corneille le « nègre » de Molière (il resterait à étudier de plus près le cas de Dom Garcie 42 -, mais avec de véritables méthodes ).
MAUBERT ET
FLAUPASSANT : PRENEZ LA FILE DATTENTE !
Dernières observations : nous avons appliqué et comparé les mêmes procédures à la mise en rapport des uvres romanesques de Maupassant et Flaubert (3 romans pour ce dernier : Madame Bovary, Salammbô, LEducation sentimentale (de 1869) ; voir en annexe pour la table des 8 romans de Maupassant
Compte tenu de nos observations sur lécart constant des indices de distance obtenus, par la formule Labbé, selon les lemmes ou les formes graphiques (+4 avec ces dernières), nous pourrions estimer que le seuil, en-deçà duquel deux textes ont forcément le même auteur, est de 0.24 environ. Or voici : Madame Bovary présente un indice de distance de :
0.22 avec
Pierre et Jean
0.234 avec
Angélus
0.236 avec Fort comme la
mort
0.237 avec Notre
coeur
et une distance moyenne aux 8 romans de Maupassant, de 0.25 ! De là à supposer, voire à considérer comme certain, que cest Maupassant qui a écrit Madame Bovary
Avis aux
amateurs !
STATISTIQUES
ET ATTRIBUTION DAUTEUR
Pour ne pas conclure négativement, nous souhaitons enfin préciser ceci.
Il est clair quun calcul fin et spécifique de distance lexicale entre deux ensembles textuels serait utile à la recherche en vue de lattribution dauteur lorsque celle-ci est réellement pertinente (textes anonymes, attributions sérieusement controversées, expertises pourquoi pas dans dautres domaines que littéraires). Le manque de robustesse de lindice de MM. Labbé nous indique que, malheureusement, nous en sommes toujours à chercher une formule efficace. Mais cela nenlève rien à lutilité éventuelle de cet indice.
Cependant, il faut affirmer haut et clair quun tel indice nentrera jamais dans la logique dune échelle de pertinence absolue du type de celle que proposent MM. Labbé.
Il est enfin évident que des méthodes exploratoires de portée et de puissance générale (donc, peu fines mais fiables), comme lAFC, devront toujours être dabord employées pour cerner la question et détecter, par approximations successives, les lieux précis où les calculs de distance, sils existent un jour, pourront sappliquer utilement.
Si daventure on prenait au sérieux lidée que Corneille ait pu écrire certaines pièces signées par Molière, on gagnerait beaucoup de temps et de crédit à considérer dabord lAFC du corpus entier.
SUITE DE
LHISTOIRE
Mardi 29 Avril, M. Dominique Labbé a refusé de nous recevoir, Mme Fabienne Dumontet, journaliste au Monde, et moi, qui avais fait, avec son accord, les 650 km aller-retour de mon Université à son domicile grenoblois. Le tout, sous un prétexte fallacieux et dérisoire quil était tout à fait en mesure de nous opposer à distance, avant que jentreprenne le voyage.
« Vous ne serez pas venu pour rien », ma-t-il lancé en me remettant, avant de nous jeter sur le palier, une enveloppe contenant quelques documents et les corpus sur lesquels je souhaitais faire les tests que je viens de présenter
Mon mail du 29.04.2003 à M.
Labbé :
(NB : Joseph Rudman est un chercheur du Department of English Carnegie Mellon University Pittsburgh, USA versé notamment dans lattribution dauteur « non-traditionnelle » - Non-traditional authorship attribution, studies in eighteenth century literature. Stylistics statistics and the computer. Article disponible sur le web : http://computerphilologie.uni-muenchen.de/jg02/rudman.html , où est employée et fortement sollicitée la métaphore de lADN pour le style personnel dauteur.
Don Foster est un auteur et critique nord-américain, qui est passé des études élisabéthaines à la criminologie des écrits de serial killers, en passant par laffaire Lewinski. Son ouvrage le plus connu est Author Unknown chez Henry Holt, présenté par exemple à ladresse http://archive.salon.com/books/review/2000/11/02/foster/ ).
Cher collègue,
Comme elle a dû vous en informer, Fabienne Dumontet m'a demandé de l'accompagner lors de la visite dont elle est convenue avec vous, mardi 29 après-midi. Elle m'a indiqué que vous étiez d'accord avec cette éventualité.
Je me réjouis sans réserve de cette occasion de rencontre et de discussion.
Mais comme je ne veux pas vous donner la moindre impression de duplicité, je dois vous préciser dans quelles conditions cette proposition prend place.
C'est Claude Blum qui, contacté par F.Dumontet à la recherche d'éclairages multiples sur l'affaire dont elle s'occupe pour 'Le Monde', lui a donné (avec mon accord préalable !) mes coordonnées. J'ai répondu avec plaisir à sa démarche et cela m'a donné l'occasion de prendre connaissance de l'état récent de la discussion Molière-Corneille, que je n'avais plus suivie depuis Rouen en 2002.
Je ne vous cacherai donc pas plusieurs points importants :
(1) ayant lu votre article du 'Journal of quantitative linguistics', vos développements en français accessibles sur votre page Web, j'ai une forte attente de pouvoir tester moi-même vos corpus d'étude, et aussi votre corpus d'étalonnage; en particulier, j'ai beaucoup de mal à croire que deux auteurs 'indiscutablement' différents ne puissent pas produire deux textes présentant une distance < 0.2 . J'ai aussi du mal à croire que la lemmatisation puisse modifier sérieusement les résultats (hormis sans doute les seuils s'ils ont une pertinence). Donc, je suppose que vous pouvez me prêter le corpus Molière-Corneille et le corpus du test Brunet.
(2) j'avoue pencher actuellement du côté des arguments de Georges Forestier que je viens de lire.
(3) en effet je trouve 'a priori' que la seule comparaison des vocabulaires 'massifs', même si elle est menée avec rigueur, reste un argument très insuffisant à établir une réelle parenté TEXTUELLE; d'ailleurs, je récuserais volontiers votre notion de 'distance intertextuelle' ; même si en effet le passage de V à N semble un pas vers la textualité, il est tout à fait élémentaire ! Même dans l'hypothèse où on aurait étudié le vocabulaire dans ses collocations, son engrenage etc. je persisterais dans la prudence de parler de 'distance lexicale' ('inter' ne servant de toute façon à rien). Profondément spitzérien, j'aurais pour idéal la formalisation d'un faisceau complexe et hiérarchisé de traits, de portée globale et/ou locale, permettant de caractériser (individuer, pour reprendre L.Jenny) un texte non par contraste avec un corpus de référence, mais le plus longtemps et le plus loin possible, par ce que l'analyse 'fait monter' en lui (en ce texte).
(4) en outre, j'avais déjà été assez choqué par l'emploi que vous faites des termes de 'preuve', 'prouver', 'proof' etc. Vous écrivez même, p.214 du 'JQL', "it also PROVES that Corneille PROBABLY wrote..." ce qui mérite pour le moins une explication... de texte. De plus, en vous référant à Rudman, vous cautionnez son analogie entre le style d'auteur et l'ADN, à mes yeux INACCEPTABLE car il s'agit d'une de ces naturalisations bien typiques de la techno-science qui envahit le champ des sciences humaines. Il en va de même pour la métaphore d' 'empreinte digitale' qu'il vous arrive d'employer. De plus, ces analogies introduisent la connotation du 'détective' (voire du policier, notamment si je lis Don Foster), c'est-à-dire l'idée très fallacieuse d'un 'dévoilement' qui deviendrait la mission du nouveau philologue... Cette prévention à l'égard de tout naturalisme vise bien sûr également à nous éviter de retomber dans les ornières du passé concernant la figure de l'auteur, la socio-biographie sans rivages.
(5) j'avoue enfin, pour faire bref, pencher plutôt du côté des tenants d'une démarche plus exploratoire (ou heuristique induite) que conclusive en matière de statistique lexicale; je crois que vous faites le choix inverse. Pour ma part, je ne nie pas du tout l'intérêt des calculs les plus massifs et les plus robustes (s'ils le sont), à condition que leur fonction soit bien de venir dialoguer avec les hypothèses des experts, 'dialoguer' ne signifiant pas seulement confirmer/infirmer, mais aussi et surtout nuancer, infléchir, relancer. C'est pourquoi je me sens mal à l'aise, en tant que chercheur dans les mêmes brisées que vous, lorsque, sans doute afin de frapper les esprits et d'obtenir l'attention, vous annoncez une redistribution radicale des cartes, 'grâce aux mathématiques appliquées'. Bien que convaincu, comme vous, qu'il y a AUSSI chez les littéraires 'installés' des comportements conservateurs, voire des sinécures et des fonds de commerce (j'insiste sur le 'AUSSI'), je n'en suis pas moins confiant dans les certitudes partagées par eux le plus largement et fondées sur des travaux dynamiques et constamment renouvelés selon leurs méthodes propres (qui, la réaction de G.Forestier nous l'indique, ne rejettent pas 'par principe' les aspects statistiques). Notre 'mission' ou notre 'apport' pourrait dès lors consister notamment à renforcer le goût et la compétence aux formalismes, aux explicitations et aux calculs chez nos interlocuteurs, plutôt que de tirer les conclusions à leur place.
Vous voyez que je ne vous cache rien de mes soucis.
Je ne parle pas ici de la lemmatisation. Si nous en avons le temps après avoir complètement examiné ce premier dossier, nous pourrons l'aborder. Mais je n'y vois pas les mêmes difficultés entre nous.
J'espère bien entendu que ces précisions ne vous choquent pas.
Bien cordialement et à mardi
Jean-Marie Viprey
Le programme dapplication de la formule de « distance
intertextuelle », écrit sous ®Microsoft VBPro (avons-nous bien appliqué les
préconisations de MM. Labbé ?)
fich = "c:/DOSSIER/distance_frm.txt"
Set fso =
CreateObject("Scripting.FileSystemObject")
Set outh =
fso.CreateTextFile(fich, True)
fich = "c:/DOSSIER/distance_compare.txt"
Set fso =
CreateObject("Scripting.FileSystemObject")
Set outj =
fso.CreateTextFile(fich, True)
Dim voc(2, 21, 10000) As Variant
Dim frk(2, 21, 10000) As Single
Dim n_v(2, 21) As Long
Dim lentex(2) As Long
Dim frq As
Long
Dim matrice(50, 50)
For z = 1
To 67
Print z;
Time
For zz = 1
To 67
If z
<> zz Then
For i = 1 To 2
For j = 1 To 21
For k = 1 To 10000
voc(i, j, k) =
""
frk(i, j, k) =
0
Next k
n_v(i, j) =
0
Next j
lentex(i) =
0
Next i
lentexx =
0
distot =
0
lentot =
0
fich =
"c:/DOSSIER/" & z & "_lem.txt"
Open fich For Input As
#1
Do Until EOF(1)
Line Input #1,
ligne
If ligne <> ""
Then
tbl = 0
tbl = InStr(ligne, Chr(9))
If tbl > 0 Then
mot = Left(ligne, tbl - 1)
frq = Right(ligne, Len(ligne) - tbl)
lentex(1) = lentex(1) + frq
End If
lm =
Len(mot)
If lm > 21 Then lm =
21
n_v(1, lm) = n_v(1, lm) + 1
voc(1, lm, n_v(1, lm)) = mot
frk(1, lm, n_v(1, lm)) = frq
End If
Close #1
fich =
"c:/DOSSIER/" & zz & "_lem.txt"
Open fich For Input As
#1
Do Until EOF(1)
Line Input #1,
ligne
If ligne <> ""
Then
tbl = 0
tbl = InStr(ligne, Chr(9))
If tbl > 0 Then
mot = Left(ligne, tbl - 1)
frq = Right(ligne, Len(ligne) - tbl)
lentex(2) = lentex(2) + frq
End If
lm =
Len(mot)
If lm > 21 Then lm =
21
n_v(2, lm) = n_v(2, lm) + 1
voc(2, lm, n_v(2, lm)) = mot
frk(2, lm, n_v(2, lm)) = frq
End If
Loop
Close #1
len1 = lentex(1)
len2 = lentex(2)
If len1 > len2 Or len1 = len2 Then
'recherche du texte le plus long et calcul de la frq théorique
'''''''''''
If lentex(1)
> lentex(2) Then
bbb =
1
aaa = 2
coef = lentex(1) / lentex(2)
lentex(1) = 0
Else
bbb =
2
aaa =
1
coef = lentex(2) / lentex(1)
lentex(2) = 0
End If
'''''''''''''
For i = 1 To 21
For j = 1 To n_v(bbb, i)
frk(bbb, i, j) =
Round(frk(bbb, i, j) / coef, 4)
If frk(bbb, i,
j) > 1 Or frk(bbb, i, j) = 1 Then
lentex(bbb) =
lentex(bbb) + frk(bbb, i, j)
End If
Next j
Next i
''''''''''''''
'calcul A vers
B
For i = 1 To 21
For j = 1 To n_v(aaa, i)
tv =
0
dis1 = 0
For k = 1 To n_v(bbb, i)
If voc(bbb, i,
k) = voc(aaa, i, j) Then
tv =
1
'If frk(bbb, i,
k) = 1 Or frk(bbb, i, k) > 1 Then
dis1 = Abs(frk(bbb, i, k) - frk(aaa, i, j))
If dis1 > 0.5 Then distot = distot +
dis1
'End If
'suppression de l'item
dans V2
For l = k To n_v(bbb, i) - 1
voc(bbb, i, l) =
voc(bbb, i, l + 1)
frk(bbb, i, l) =
frk(bbb, i, l + 1)
Next l
n_v(bbb, i) =
n_v(bbb, i) - 1
End If
Next k
If tv = 0
Then
dis1 = frk(aaa,
i, j)
distot = distot
+ dis1
End If
'Print i; j; frk(aaa,i, j); voc(aaa,i, j); dis1
Next j
Next i
For i = 1 To 21
For j = 1 To n_v(bbb, i)
If frk(bbb, i,
j) = 1 Or frk(bbb, i, j) > 1 Then
dis1 = frk(bbb,
i, j)
distot = distot
+ dis1
End If
Next j
Next i
indi =
Round(distot / (lentex(aaa) + lentex(bbb)), 3)
'If len1 > len2 Or len1 = len2 Then
outj.writeline z
& Chr(9) & zz & Chr(9) & len1 & Chr(9) & len2 &
Chr(9) & _
coef &
Chr(9) & indi
'End If
matrice(z, zz) = indi
matrice(zz, z) = indi
End If
Else
matrice(z, zz) =
0
End
If
Next
zz
Next
z
For i = 1
To 50
For j = 1
To 50
outh.write matrice(i, j) &
Chr(9)
Next
j
outh.writeline
Next
i
outh.Close
outj.Close
Table de correspondance des numéros et des textes du corpus Corneille/Molière :
uvres « attribuées » à Corneille :
1 Mélite
2 Clitandre
3 La Veuve
4 La Galerie du Palais
5 La Suivante
6 La Comédie des Tuileries. acte III.
7 Médée
8 La Place Royale
9 L'Illusion
10 Le Cid
11 Cinna
12 Horace
13 Polyeucte
14 Pompée
15 Le Menteur
16 La Suite du Menteur
17 Rodogune princesse des Parthes
18 Théodore vierge et martyre
19 Héraclius empereur d'Orient
20 Andromède
21 Don Sanche d'Aragon
22 Nicomède
23 Pertharite roi des Lombards
24 OEdipe
25 La Toison d'or
26 Sertorius
27 Sophonisbe
28 Othon
29 Agésilas
30 Attila roi des Huns
31 Tite et Bérénice
32 Psyché
33 Pulchérie
34 Suréna
35 Psyché
uvres « attribuées » à Molière :
36 La Jalousie du barbouillé
37 Le Médecin volant
38 L'Etourdi
39 Dépit amoureux
40 Les Précieuses ridicules
41 Sganarelle ou Le Cocu imaginaire
42 Dom Garcie de Navarre
43 L'Ecole des maris
44 Les Fâcheux
45 L'Ecole des femmes
46 La Critique de l'Ecole des femmes
47 L'Impromptu de Versailles
48 Le Mariage forcé
49 La Princesse d'Elide
50 Le Tartuffe
51 Dom Juan
52 L'Amour médecin
53 Le Misanthrope
54 Le Médecin malgré lui
55 Mélicerte
56 Pastorale comique
57 Le Sicilien
58 Amphitryon
59 George Dandin
60 L'Avare
61 Monsieur de Pourceaugnac
62 Les Amants magnifiques
63 Le Bourgeois gentilhomme
64 Les Fourberies de Scapin
65 La Comtesse d'Escarbagnas
66 Les Femmes savantes
67 Le Malade imaginaire
Table de correspondance des numéros et des romans de Maupassant
4 Une Vie
5 Bel-Ami
6 Mont-Oriol
7 Pierre et Jean
8 Fort comme la mort
9 Notre cur
10 Lâme étrangère
11 Angélus